Credit: Nvidia
Ever since it became apparent that the supercomputer-like architecture of GPUs could do more than just pushing pixels, Nvidia has been refining the GPGPU architecture in its products to a razor edge. Today many machine learning and high-performance scientific and research rely on GPU technology to do the math that CPUs cant pump out quickly enough to be practical.
This branch of GPU design has become so specialized that Nvidia makes GPU products that dont connect to a display at all. The new Hopper architecture is a cutting-edge example of GPU technology designed for very non-graphical applications. Just like the Ampere-based A100 chip, the H100 will be implemented in data centers and laboratories across the world, but it represents an enormous leap in performance we havent yet seen.
High-Speed Interconnects

Credit: Nvidia
While connecting multiple GPUs together to improve gaming performance has fallen out of fashion, networking GPUs together for complex data center work in AI and other serious applications makes a lot of sense. Most of those workloads scale almost perfectly, but you need a very fast communications bus between discrete GPUs.
Hopper uses an external NVLink switch which manages GPU IO across servers at more than 900 gigabytes a second bi-directionally for each GPU. Nvidia claims that the bandwidth is more than five times as much as PCIe 5. Each NVLink switch can link up to 256 H100s!
The Transformer Engine Rolls Out

Credit: Nvidia
Tensor cores, which specialize in tensor-based mathematics are the component of modern Nvidia GPUs that accelerate the execution of machine learning algorithms and deep learning problems. This is how DLSS (Deep Learning Super Sampling) works on consumer cards but in GPGPU contexts these tensor cores can seriously improve AI performance in data centers.
The 30-series consumer GPUs already pack third-generation tensor cores, but Hopper adds in a massive improvement in the form of the Transformer Engine. This new core type exists specifically to accelerate AI training and can use mixed-precision floating-point math to maximize the number of FLOPS through smart efficiency.
When it comes to TF32, FP64, FP16, and INT8 precision numbers, the number of FLOPS has been tripled compared to the precious A100 architecture.
Date Protection While Processing

Credit: Nvidia
If your data center is running confidential workloads, then that data is likely strongly protected. At least, it is when at rest on a disk somewhere. However, a common vulnerability exploited by hackers is intercepting data while its being processed.
Nvidia has built a special hardware implementation it calls confidential computing, something the company says is a first for an accelerated computing platform. Now it doesnt matter where in the cloud you run your code, its protected by the GPU itself.
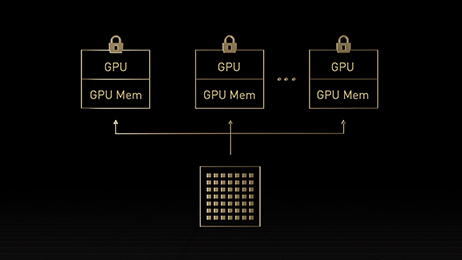
Advanced Multi-Instance GPU Technology
Credit: Nvidia
Lets say you have the opposite problem of needing more power than one GPU can offer. You may have multiple users who only need a little GPU power at a time. The second-generation MIG (Multi-Instance GPU) technology lets you create several isolated virtual GPUs that can be used by different users.
DPX Instructions Makes Algorithms (Way) More Efficient
It wouldnt be a new architecture without the inclusion of a new instruction set. DPX is a dynamic programming instruction set that builds the dynamic programming algorithmic technique into the very fabric of the GPU. Using DPX common algorithms can run as much as 7 times more quickly compared to Ampere GPUs and 40x faster than CPUs.
All the Small Things
Those are the headline breakthroughs for Hopper, but Nvidia has tinkered and improved almost every part of the GPUs design:
Better acceleration of data block transfer between global and shared memory.
Third-generation High-bandwidth Memory.
Large 50MB L2 cache.
PCIe Gen 5.
Distributed shared memory.
If youre already running A100 GPUs, the H100 promises to be a drop-in solution that will seriously uplift the performance caps you currently have. We cant wait to see what Hopper can do out in the wild!